CSDN垃圾
CSDN 垃圾不用多说了,以前只是看不到别人的博客,不过还有谷歌可以弥补,不过最近朋友和我说你的几个文章怎么变成vip独享了。。。我突然发现我的烂文字竟然还被CSDN偷偷摸摸对部分用户VIP,汗颜。。导出来算了
导出到hexo
考虑导出到hexo,搜罗了半天,没有合适的工具和代码,就自己写一个吧,需要解决三个问题
- 博客列表获取
- 博客文章内容转换成markdown
- 导出配套的图片数据
博客列表获取
CSDN 文章列表接口:
获得后从html中提取对应的xpath节点,使用lxml提取出来博客的目录link id.
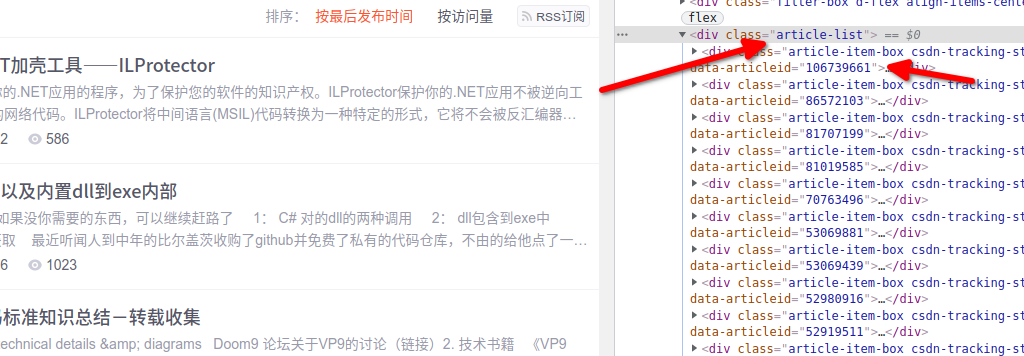
然后拼接文章接口获取到文章链接: https://blog.csdn.net/godvmxi/article/details/{link id}
二话不说贴代码
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
50
51
52
53
54
55
|
import sys
import locale
import requests
from lxml import etree
import pprint
import os
import time
print(sys.getfilesystemencoding())
print(locale.getpreferredencoding())
def get_acticle_list(user, page_start, page_end):
headers = {
"User-Agent": "Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/69.0.3497.81 Safari/537.36"
}
link_list = []
for index in range(int(page_start), int(page_end)+1 ):
print(index)
base_url= "https://blog.csdn.net/godvmxi/article/list/%s"%index
res = requests.get(url = base_url,headers=headers)
print(res.url)
print(res.status_code)
page_html = etree.HTML(res.content)
article_list = page_html.xpath('//*[@id="articleMeList-blog"]/div[2]')[0]
print(len(article_list))
for obj in article_list:
id = obj.attrib["data-articleid"]
link = "https://blog.csdn.net/godvmxi/article/details/%s\n"%id
link_list.append(link)
pprint.pprint(link_list)
with open("link.txt","w") as fd:
fd.writelines(link_list)
return link_list
def down_load_articals(link_list):
for link in link_list:
link = link.replace("\n", "")
print("Download : %s"%link)
file_name = link.split("/")[-1]
print("target file name->%s"%file_name)
cmd = "clean-mark %s -o download/%s"%(link,file_name)
print("cmd-> %s"%cmd)
os.system(cmd)
time.sleep(5)
if __name__ == "__main__" :
user= sys.argv[1]
page_start = sys.argv[2]
page_end = sys.argv[3]
link_list = get_acticle_list(user, page_start, page_end)
down_load_articals(link_list)
|
使用clean-mark 将网页转换成markdown
- 安装clean-mark
1
| npm install -g clean-mark
|
1
| clean-mark ${link} -o download/target.md"
|
处理markdown中的图片
因为图片都在csdn服务器或者其他第三方服务器,这里需要处理脚本,把对应的图片下载下来。 解析,上代码了
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
50
51
52
53
54
55
56
57
58
59
60
61
62
63
64
65
66
67
68
69
70
71
72
73
74
75
76
77
78
79
80
81
82
83
84
85
86
87
88
89
|
import sys
import locale
import requests
from lxml import etree
import pprint
import os
import time
import shutil
def handle_image_line(line, img_dir, index):
line = line.replace("\n", "").replace(".replace(")","").replace(" ", "")
print("will handle line -> " + line)
link_name = line
file_name = line.split("/")[-1]
post_fix = file_name.split(".")[-1]
if len(post_fix) > 0:
post_fix = post_fix.lower()
final_file_name = None
print("link file_name -> " + file_name + " post->" + post_fix + "<-")
cmd = None
if line.find("img-blog") > 0:
link_name = link_name.split("?")[0]
file_name = link_name.split("/")[-1]
target_file_name = img_dir + "/" + file_name
print("csdn img link name:" + link_name)
print("csdn file name : " + file_name)
print("target_file_name: " + target_file_name)
cmd="wget %s -O %s"%(link_name, target_file_name)
elif post_fix in ["png", 'jpg', 'jpeg', "gif"]:
target_file_name = img_dir + "/" + file_name
print("##normal target file : "+ target_file_name)
cmd = "wget %s -O %s"%(link_name, target_file_name)
else:
print("downlink is not support")
sys.exit(0)
print("will run cmd: " + cmd)
os.system(cmd)
line = "\n"%file_name
time.sleep(2)
return line
pass
def process_origin_markdown(source_dir, file_name, target_dir, index):
img_dir = "%s/z_csdn_%03d_%s"%(target_dir, index, file_name.replace(".md", ""))
target_file = "%s/z_csdn_%03d_%s"%(target_dir, index, file_name)
print("target file -> " + target_file)
print("target img dir-> " + img_dir)
shutil.rmtree(path = img_dir,ignore_errors=True)
os.mkdir(img_dir)
out_lines = []
with open(source_dir + "/" +file_name, "r") as fd:
lines = fd.readlines()
for line in lines:
if line.startswith("link"):
continue
if line.startswith("keywords:"):
line = "tags: CSDN\n"
if line.startswith("![]") :
line = handle_image_line(line, img_dir, index) + "\n"
print("img line : " + line)
out_lines.append(line)
if len(out_lines) > 0 :
with open(target_file, "w+") as fd:
fd.writelines(out_lines)
if __name__ == "__main__":
source_dir = sys.argv[1]
target_dir = sys.argv[2]
start_files = int(sys.argv[3])
end_files = int(sys.argv[4])
source_file_list = os.listdir(source_dir)
index = 1
for file in source_file_list :
if index > end_files:
break
print("########################## handle file -> start: %3d end:%3d index:%3d file: %s"%(start_files,end_files, index, file))
if index >= start_files:
process_origin_markdown(source_dir, file, target_dir,index)
index = index + 1
|
手动处理部分冲突问题
因为hexo对部分的关键词不好,这里需要对部分关键词进行修改,比如:
link 删掉即可
description , 手动截断或者删除特殊字符
脚本提供了调试方法:
1
2
3
4
5
6
| python3 get_img.py download/ /srv/chia/disk/1/work/code/github/blog/source/_posts/ 74 90
arg1: 原始markdown文件位置
arg2: hexo博客陌路
arg3: 起始文件index
arg4: 结束文件index
|
关于程序与设计 | kernel & MCU & ASIC Lover,Software Engineer | 这里是 @蛋种 的个人博客,与你一起发现更大的世界。